 medium.com
medium.com

The article discusses the necessity of shuffle support in database operations, highlighting its benefits in preventing memory allocation failures, enhancing scalability, and improving performance. It emphasizes the role of shuffle in redistributing data for more efficient processing.
Main Points
Importance of Shuffle Support
Shuffle support is crucial for addressing the challenges of memory allocation failure, enhancing the horizontal scalability of compute nodes, and improving overall performance by breaking down large hash tables into smaller, more manageable pieces.
Insights
Solving the problem of memory allocation failure due to large hash tables
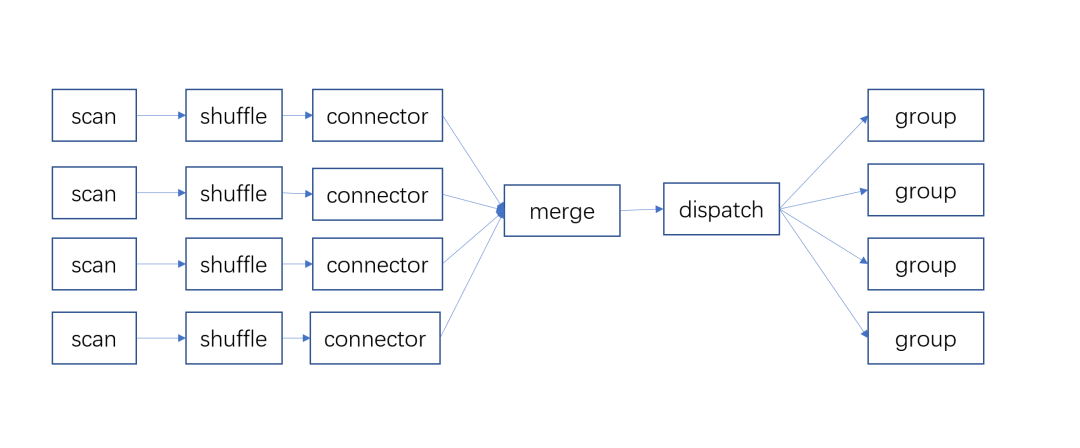
Taking merge group as an example, since all data need to be merged together, if the cardinality of the final merged hash table is too large, the required memory allocation will be very large, leading to memory allocation failure. Exceeding the memory limit of a single CN (compute node) and not considering the spill scenario can also cause out-of-memory (OOM) errors. Meanwhile, shuffle can split a large hash table into multiple smaller hash tables for processing.
Enhancing the horizontal scalability of compute nodes
Still taking merge group as an example, since all data need to be merged together, processing is done in single concurrency on a single CN. If the hash table has a large cardinality, this step becomes slow and a bottleneck, and adding more CNs cannot speed up such queries. Shuffle group does not have this single-point bottleneck.
Improving performance
When hash tables are too large, random access to the hash table leads to a very high probability of cache misses, and cache misses significantly reduce performance. By using shuffle to split the hash table into multiple smaller hash tables for processing, the cache hit rate for random access to each small hash table is greatly increased, thereby improving overall performance.